To calculate the solar panel efficiency, you need to divide its maximum power output (Watts, i.e. 500W) by its total area in square meters (let’s say 2.3 sq.m.), then divide it again by the STC Irradiance value (1000 W/sq.m.). The result will then be multiplied by 100 to obtain the percent value. This is the simplest method on how to calculate solar panel efficiency.
The solar panel efficiency calculator will appear above in a few seconds.
where, Pmax = solar panel peak power (in Watts) Area = length x width of the solar panel (in sq.m.) 1000 = Standard Test Condition (STC) irradiance (in Watts/sq.m.)
By this simple solar module efficiency formula, you will know how efficient a solar panel is, aside from looking it up on its specification sheet or at its nameplate. As the efficiency of the solar panel will be calculated by this formula, you will now be able to confirm the module efficiency details when you see a solar panel using this method.
Try our tool below to check how efficient your solar PV module is. Just enter the correct values for the solar panel maximum power at STC, length of the module, and its width in millimeters (mm). Click the “Calculate” button right after entering the required data.
In case you missed it, you can also try our voltage drop calculator to validate the solar cable size for your PV system.
What is solar panel efficiency?
Solar panel efficiency can be simply described as the ratio of the module’s power absorption to the input irradiance on standard test conditions. The power absorption of the module is the maximum solar module Wattage divided by its surface area. On the other hand, the input irradiance is the radiant power supplied per unit area which is equal to 1000 Watts per square meter at Standard Test Conditions (STC).
Therefore, solar module efficiency tells us how effective a solar panel is in transforming solar energy into useful electricity through the Photovoltaic effect.
The challenge on the part of solar panel manufacturers mainly boils down to improving solar module efficiency. They aim to build a module that effectively converts solar energy to useful electricity using less surface area. Thus, the worth of a solar panel increases in proportion to its efficiency.
Solar Panel Efficiency Calculation
Most of the time, solar manufacturers will readily show the details about the PV module’s efficiency on its specifications sheet or at the back of the panel itself. However, if you want to know how the solar panel efficiency is calculated, you can follow the simple steps below:
Step 1. Know the module’s maximum power capacity
You can easily know this by looking at the module datasheet, or by looking at the back of the solar panel itself. It will have its details shown on the back sticker usually. They normally label it as Pmax or maximum power of the module. They normally put it on the model name itself so this is not a hard thing to do.
Step 2. Get the module’s physical dimension
This step is as straightforward as it seems. Just take a tape measure, get the length and width of the solar panel and you’re done. Or, you can also look for its dimension from the module’s specification sheet.
Step 3. Get the power per unit area of the solar module
Once you have the measurements of the module’s length and width, you can now get its power per unit area. Just divide the solar panel’s maximum power capacity into its entire area. This will be in terms of Watts per square meter.
Step 4. Know the solar irradiance value at STC
Irradiance is defined as the radiant power (in Watts) received by the unit area of the surface (in square meter). In solar panel tests, this means the amount of radiant energy that is beamed to the surface of the module.
Moreover, STC stands for Standard Test Conditions. This is the set of criteria that the solar industry follows for the conditions under which a solar panel will be tested. The conditions are as follows:
Solar Cell Temperature at 25°C. This refers to the temperature of the solar cell itself, not the temperature of the surrounding.
Solar Irradiance at 1000 Watts per square meter. This refers to the amount of light energy received by a unit surface at a given time.
Air Mass at 1.5
Step 5. Solar panel efficiency calculation
After carefully following the simple steps above, you will have all you need to know how efficient a certain solar panel is. This is done by dividing the power per unit area of the solar module (in Watts/sq.m.) by the solar irradiance at STC which is 1000 Watts/sq.m.
The ratio that you get after the calculation will be the efficiency of the solar PV module that you are looking for.
Solar Panel Efficiency Breakthroughs
What affects solar panel efficiency?
The limitation in solar cell efficiency directly affects how efficiently a solar panel converts solar energy into electricity.
“In physics, the Shockley–Queisser limit (also known as the detailed balance limit, Shockley Queisser Efficiency Limit or SQ Limit, or in physical terms the radiative efficiency limit) refers to the maximum theoretical efficiency of a solar cell using a single p-n junction to collect power from the cell where the only loss mechanism is radiative recombination in the solar cell. It was first calculated by William Shockley and Hans-Joachim Queisser at Shockley Semiconductor in 1961, giving a maximum efficiency of 30% at 1.1 eV.” – Wikipedia.
This boils down to the materials used, the reflective efficiency, and how well the solar panel handles heat.
The efficiency of solar cells
Solar cell efficiency refers to the ratio of the power output of a solar cell to its power input while considering its surface area. It is the portion of energy in the form of sunlight that can be converted via photovoltaics into electricity by the solar cell.
It is true that solar cell efficiency directly affects solar panel efficiency. However, we need to understand that they don’t equate to each other.
You may ask, why? Isn’t a solar panel made up of individual solar cells? Yes, you are correct. However, when calculating the efficiency of a solar PV module, you take into consideration the whole surface area of the panel. This is because of the gaps between solar cells inside the solar panel. Additionally, you will also need to consider the surface area of the aluminum frames since it is also part of the PV module.
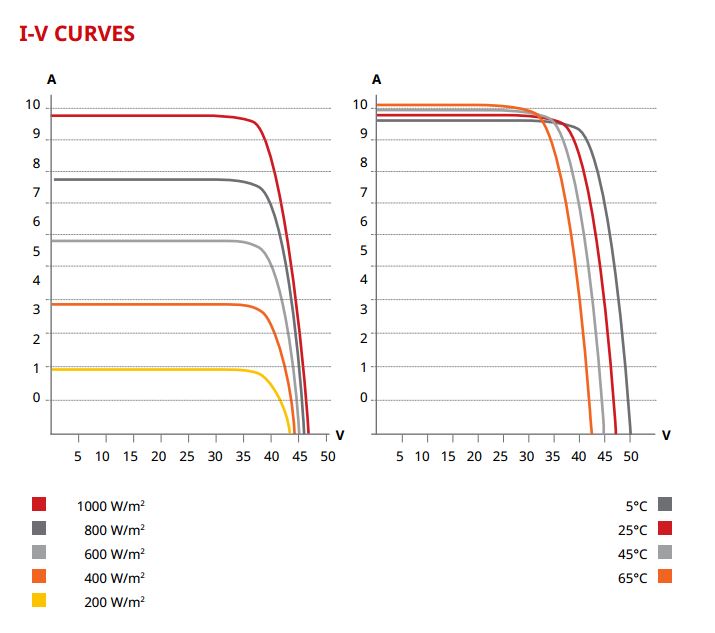
What is the solar cell IV Curve?
Moreover, when we look at the power output of a PV module on its datasheet we will also see its IV Curve. The IV Curve is also known as the Current (I) Voltage (V) characteristic of an electrical device like a solar cell.
Typically, this is represented as a graph that shows all the possible power points of the power output at any given set of conditions. The set of conditions includes the solar cell temperature, air mass, and irradiance (or light intensity).
Solar cell manufacturers conduct tests to see how their products perform in various temperatures and irradiance level exposure. The results will then be reflected in a graphical format and the maximum value they get in terms of Watts will be the maximum power capacity of the certain solar cell.
Why is solar panel efficiency important when selecting panels?
The importance of solar panel efficiency lies in its impact on energy production, space efficiency, cost savings, design flexibility, and environmental considerations. Efficiency is a critical factor to consider when selecting solar panels, in conjunction with other relevant criteria, in order to identify the most appropriate panels that align with specific solar energy requirements.
While higher-efficiency panels typically entail a greater initial cost when compared to lower-efficiency panels, their long-term advantages, such as augmented energy production and cost savings, often justify the initial investment. Nevertheless, it is crucial to meticulously assess the individual circumstances, encompassing factors like available space, budgetary constraints, and financial objectives, to accurately evaluate the overall impact of panel efficiency on costs.
Endpoints
Looking back at the past several decades, we can see how the efficiency of solar PV modules has increased significantly. And, this will eventually continue to go up to its peak.
It is great to see how the solar industry is thriving towards better solar module efficiency. Considering the benefits we can get from it, we know this is going in the right direction. Whether it be an off-grid solar system, a grid-tie, or a hybrid system, improvements in solar panel efficiency will always be valuable.
Eventually, we will have solar power plants that produce clean energy even in a little amount of space available. More importantly, the cost has also come down tremendously. This makes utility-scale solar among the cheapest electrical power source you can build.
If you want to learn more about solar power and other renewable energy sources, sign up for our email list now and be part of the Solar Powered Fam!
Summary
Article Name
Calculate Solar Panel Efficiency with Simplest Method
Description
Solar panel efficiency is the ratio of the module's Wattage per unit area (module's Pmax/total area in sq.m.) to the STC Irradiance value (1000W/sq.m.).
He loves to read news and articles about renewable energy and technology. He is experienced in the solar energy industry. He loves to write articles, guides, and tutorials about solar PV technology.




")


? The Simplest Answer")








")


? The Simplest Answer")









Where is the calculator? I thought there used to be one here.
Hello there! Kindly refresh the page if you still can’t see our solar panel efficiency calculator. Thank you for visiting our website!